知识点
相关文章
更多最近更新
更多Twitter Storm 分布式RPC
2019-03-02 23:38|来源: 网路
分布式RPC
- DRPCClient client = new DRPCClient("drpc-host", 3772);
- String result = client.execute("reach", "http://twitter.com");
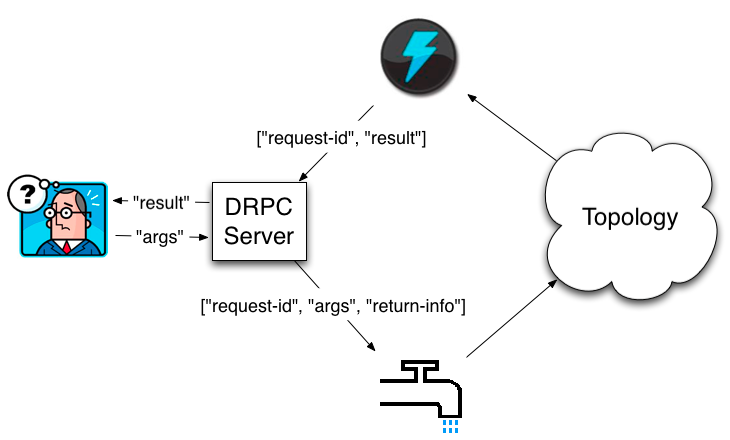
客户端发送功能名称及功能所需参数到DRPC服务器去执行。图中的拓扑实现了此功能,它使用DRPCSpout从DRPC服务器接收功能调用流。每个功能调用通过DRPC服务器使用唯一ID标记,随后拓扑计算结果,在拓扑的最后,一个称之为“ReturnResults”的bolt连接到DRPC服务器,把结果交给这个功能调用(根据功能调用ID),DRPC服务器根据ID找到等待中的客户端,为等待中的客户端消除阻塞,并发送结果给客户端。
- public static class ExclaimBolt implements IBasicBolt {
- public void prepare(Map conf, TopologyContext context) {
- }
-
- public void execute(Tuple tuple, BasicOutputCollector collector) {
- String input = tuple.getString(1);
- collector.emit(new Values(tuple.getValue(0), input + "!"));
- }
-
- public void cleanup() {
- }
-
- public void declareOutputFields(OutputFieldsDeclarer declarer) {
- declarer.declare(new Fields("id", "result"));
- }
-
- }
-
- public static void main(String[] args) throws Exception {
- LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("exclamation");
- builder.addBolt(new ExclaimBolt(), 3);
- // ...
- }
如你所见,代码非常少。当创建LinearDRPCTopologyBuilder时,你把这个拓扑的DRPC功能名称告诉storm。一个DRPC服务器可以协调许多功能,功能名称用于区别不同的功能,首先声明的bolt将接收一个输入的2-tuples,第一个字段是请求ID,第二个字段是请求参数。LinearDRPCTopologyBuilder认为最后的bolt会发射一个输出流,该输出流包含[id, result]格式的2-tuples。最后,所有拓扑中间过程产生的元组(tuple)都包含请求id作为其第一个字段。
- LocalDRPC drpc = new LocalDRPC();
- LocalCluster cluster = new LocalCluster();
-
- cluster.submitTopology("drpc-demo", conf, builder.createLocalTopology(drpc));
-
- System.out.println("Results for 'hello':" + drpc.execute("exclamation", "hello"));
-
- cluster.shutdown();
- drpc.shutdown();
- bin/storm drpc
- drpc.servers:
- - "drpc1.foo.com"
- - "drpc2.foo.com"
- StormSubmitter.submitTopology("exclamation-drpc", conf, builder.createRemoteTopology());
- LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("reach");
- builder.addBolt(new GetTweeters(), 3);
- builder.addBolt(new GetFollowers(), 12)
- .shuffleGrouping();
- builder.addBolt(new PartialUniquer(), 6)
- .fieldsGrouping(new Fields("id", "follower"));
- builder.addBolt(new CountAggregator(), 2)
- .fieldsGrouping(new Fields("id"));
1. GetTweeters获取tweeted the URL的用户。它转换一个[id, url]形式的输入流到[id, tweeter]形式的输出流。每个url元组将映射到多个tweeter元组。
2. GetFollowers获取这些tweeter的追随者。它转换一个[id, tweeter]形式的输入流到[id, follower]形式的输出流。跨所有任务,当某人追随多个tweeter,这些tweeter又tweeted相同的URL时,这可能会得到重复的追随者。
- public static class PartialUniquer implements IRichBolt, FinishedCallback {
- OutputCollector _collector;
- Map<Object, Set<String>> _sets = new HashMap<Object, Set<String>>();
-
- public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
- _collector = collector;
- }
-
- public void execute(Tuple tuple) {
- Object id = tuple.getValue(0);
- Set<String> curr = _sets.get(id);
- if(curr==null) {
- curr = new HashSet<String>();
- _sets.put(id, curr);
- }
- curr.add(tuple.getString(1));
- _collector.ack(tuple);
- }
-
- public void cleanup() {
- }
-
- public void finishedId(Object id) {
- Set<String> curr = _sets.remove(id);
- int count;
- if(curr!=null) {
- count = curr.size();
- } else {
- count = 0;
- }
- _collector.emit(new Values(id, count));
- }
-
- public void declareOutputFields(OutputFieldsDeclarer declarer) {
- declarer.declare(new Fields("id", "partial-count"));
- }
- }
在底层,CoordinatedBolt用于检测一个bolt何时收到该请求ID的所有元组。CoordinatedBolt使用direct stream管理协调。
DRPCSpout发射[args, return-info],return-info是DRPC服务器的主机和端口,还有DRPC服务器生成的ID。
- DRPCSpout
- PrepareRequest(生成一个请求ID,创建一个返回信息流,一个参数流)
- CoordinatedBolt包装器和直接分组
- JoinResult(同返回信息一起连接结果)
- ReturnResult(连接DRPC服务器并返回结果)
- LinearDRPCTopologyBuilder是一个构建在Storm原语之上的高层次抽象的好例子。
- 同时编排处理多个请的KeyedFairBolt
- 如何直接使用CoordinateBolt
转自:http://chenlx.blog.51cto.com/4096635/748348
相关问答
更多-
什么是分布式系统?[2022-11-11]
一、DFS为何物? DFS 即微软分布式文件系统的简称,系统管理员可以利用它来有效的整合网络资源,并把这些资源以单一的层次结构呈现给网络用户。管理员利用它可以把资源发布成一 个树形结构,这样大大简化了为用户进行资源配置和对资源管理的工作量。我们可以在不同的机器上调整和移动文件,这不会影响到用户的访问。 二、为什么要使用DES? 1、DFS使用了现有网络中的Share权限,管理员不必进行新的配置 2、通过一个DFS树形结构用户就可以访问多个网络资源,而不用再把远程驱动器映射到本地共享资源中。 3、DFS可以配 ... -
什么是分布式系统?[2024-03-23]
分布式系统(distributed system)是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。内聚性是指每一个数据库分布节点高度自治,有本地的数据库管理系统。透明性是指每一个数据库分布节点对用户的应用来说都是透明的,看不出是本地还是远程。在分布式数据库系统中,用户感觉不到数据是分布的,即用户不须知道关系是否分割、有无复本、数据存于哪个站点以及事务在哪个站点上执行等。 故名思义,分布式 ... -
免责声明:我写了您在上述问题中引用的文章 。 但是,我对“任务”的概念有些困惑。 任务是组件的运行实例(spout还是螺栓)? 执行者有多个任务实际上是说执行者多次执行相同的组件,我是否正确? 是的,是的。 此外,在一般的并行性意义上,Storm将为一个喷口或螺栓生成一个专用的线程(执行器),但是由具有多个任务的执行器(线程)对并行性的贡献是什么? 每个执行器运行多个任务不会增加并行级别 - 执行程序总是有一个线程用于其所有任务,这意味着任务在执行程序上连续运行。 正如我在文章中写道,请注意: 在拓扑开始后 ...
-
您可以使用Apache Kafka作为分布式和强大的队列,可以处理大量数据,并使您能够将邮件从一个端点传递到另一个端点。 风暴不是队列。 它是一种具有分布式实时处理能力的系统,意味着可以对实时数据进行并行执行各种操作。 这些工具的共同流程(据我所知)如下: 实时系统 - > Kafka - > Storm - > NoSql - > BI(可选) 所以你有你的实时应用程序处理大量的数据,发送到卡夫卡队列。 风暴从卡夫卡拉取数据并应用一些必要的操纵。 在这一点上,您通常希望从这些数据中获得一些好处,因此您可以 ...
-
Storm中的数据并行性(Data parallelism in Storm)[2022-01-14]
你可以使用fieldsGrouping 。 您可以声明一个字段,通过该字段对元组进行分组(在您的情况下为id )。 我只是假设您的输入流是具有id和body字段的JSON对象 {"id":"1234","body":"some body"} 还假设您的拓扑结构有一个喷口,两个螺栓,即BoltA和BoltB。 在BoltB中,覆盖declareOutputFields方法并填写详细信息。 public void declareOutputFields(OutputFieldsDeclarer declare ... -
无法使用kafka-storm向apache storm提交拓扑(Unable to submit topology to apache storm using kafka-storm)[2022-04-07]
我最终通过使用maven repo中预编译的storm-kafka版本并在拓扑中添加过滤器螺栓而不是在spout本身中进行过滤来解决这个问题。 从而消除了对storm-core和storm-kafka本地编译的jar文件的需求。 这不是一个“解决方案”,但它是解决问题的一种方法。 I eventually worked around this problem by using a pre-compiled version of storm-kafka from a maven repo and adding ... -
我从来没有听说过DSMS一词,但是看一下维基百科上的描述,我认为Storm绝对可以说是DSMS。 来自维基百科: 它类似于数据库管理系统(DBMS)[...]但是,与DBMS相比,DSMS执行连续查询,该查询不仅执行一次,而且是永久安装的。 这听起来就像Storm一样。 但请注意,在Storm的情况下,它通常与DBMS结合使用。 例如,Storm可以提供One-time queries , unlimited secondary storage等,维基百科说这与DSMS结合时缺乏DSMS。 I had ne ...
-
只需按照群集设置指南操作: https://storm.apache.org/documentation/Setting-up-a-Storm-cluster.html 对于伪分布式设置,请在单台计算机中运行所有守护程序(ZK,Nimbus和一个单独的主管)。 Just follow the cluster setup guide: https://storm.apache.org/documentation/Setting-up-a-Storm-cluster.html For pseudo distri ...
-
错误是由于事实 - BlockingQueue未在输出收集器中初始化; The error is due to the fact -- The BlockingQueue was not initilaized in the output collector;
-
除非出现问题,否则你已经完成了。 当您向Storm提交拓扑时,Nimbus服务会通过遍布整个群集的Supervisor进程查看群集上的负载。 然后,Nimbus为拓扑运行提供一定数量的资源。 这些资源通常遍布集群中的各个Supervisor节点,并且它们将并行处理元组。 Nimbus偶尔会重新审视这些决策并更改哪些节点处理什么以尝试保持群集中的负载平衡。 作为用户,您永远不应该注意到这个过程。 假设您的Storm集群设置正确,您唯一需要做的就是提交拓扑。 Storm为您处理整个多节点并行处理事务。 也就是说 ...