开源项目
知识点
相关文章
更多最近更新
更多Netty基于流的传输处理
2019-04-20 15:46|来源: 网路
在TCP/IP的基于流的传输中,接收的数据被存储到套接字接收缓冲器中。不幸的是,基于流的传输的缓冲器不是分组的队列,而是字节的队列。 这意味着,即使将两个消息作为两个独立的数据包发送,操作系统也不会将它们视为两个消息,而只是一组字节(有点悲剧)。 因此,不能保证读的是您在远程定入的行数据。 例如,假设操作系统的TCP/IP堆栈已收到三个数据包:
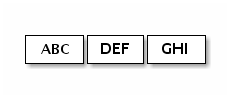
由于基于流的协议的这种通用属性,在应用程序中以下面的碎片形式(只是其中的一种)读取它们的机会很高:
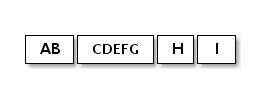
因此,接收部分,无论是服务器侧还是客户端侧,都应该将接收到的数据碎片整理成逻辑可由应用容易地理解的一个或多个有意义的帧。 在上述示例的情况下,接收的数据应该如下成帧:
针对上面的问题,下面列出了两个解决方案。
第一个解决方案
现在我们回到TIME客户端示例。在这里有同样的问题。 32位整数可以算是非常少量的数据量了,并且不可能经常被分段。 然而,问题是它可以分割,并且碎片的可能性将随着流量增加而增加。
简单的解决方案是创建一个内部累积缓冲区,并等待所有4个字节被接收到内部缓冲区。 以下是修正的TimeClientHandler实现,它修复了问题:
package cn.netty.time;
import java.util.Date;
public class TimeClientHandler extends ChannelInboundHandlerAdapter {
private ByteBuf buf;
@Override
public void handlerAdded(ChannelHandlerContext ctx) {
buf = ctx.alloc().buffer(4); // (1)
}
@Override
public void handlerRemoved(ChannelHandlerContext ctx) {
buf.release(); // (1)
buf = null;
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf m = (ByteBuf) msg;
buf.writeBytes(m); // (2)
m.release();
if (buf.readableBytes() >= 4) { // (3)
long currentTimeMillis = (buf.readUnsignedInt() - 2208988800L) * 1000L;
System.out.println(new Date(currentTimeMillis));
ctx.close();
}
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {
cause.printStackTrace();
ctx.close();
}
}
ChannelHandler有两个生命周期侦听器方法:handlerAdded()和handlerRemoved()。 只要不会阻塞很长时间,您就可以执行任意初始化任务。首先,所有接收到的数据应累加到
buf中。然后,处理程序必须检查
buf是否有足够的数据(在此示例中为4个字节),当足够时就继续进行实际的业务逻辑。否则,在有更多数据到达时Netty将再次调用channelRead()方法,最终累积到达4个字节再执行实际的业务。
第二个解决方案
虽然第一个解决方案已经解决了TIME客户端的问题,但修改的处理程序看起来不那么干净。想象如果一个更复杂的协议,它由多个字段组成,例如:可变长度字段等。上面的ChannelInboundHandler实现很快就无法维护了。
可能已经注意到,可以向ChannelPipeline添加多个ChannelHandler,因此,可将一个单片的ChannelHandler拆分为多个模块,以降低应用程序的复杂性。 例如,可将TimeClientHandler拆分为两个处理程序:
TimeDecoder处理碎片问题
TimeClientHandler的初始简单版本
幸运的是,Netty提供了一个可扩展类,可以帮助我们方便地编写:
package cn.netty.time;
public class TimeDecoder extends ByteToMessageDecoder { // (1)
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) { // (2)
if (in.readableBytes() < 4) {
return; // (3)
}
out.add(in.readBytes(4)); // (4)
}
}
ByteToMessageDecoder是ChannelInboundHandler的一个实现,它使得处理碎片问题变得容易。ByteToMessageDecoder在接收到新数据时,使用内部维护的累积缓冲区调用decode()方法。decode()可以决定在累积缓冲区中没有足够数据的情况下不添加任何东西。 当接收到更多数据时,ByteToMessageDecoder将再次调用decode()。如果
decode()将对象添加到out,则意味着解码器成功地解码了消息。ByteToMessageDecoder将丢弃累积缓冲区的读取部分。要记住,不需要解码多个消息。ByteToMessageDecoder将继续调用decode()方法,直到它没有再有任何东西添加。
现在我们有另一个处理程序插入ChannelPipeline,应该在TimeClient中修改ChannelInitializer实现:
b.handler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new TimeDecoder(), new TimeClientHandler());
}
});
如果您喜欢折腾,也可以想尝试使用ReplayDecoder,这简化了解码器更多的工作。但需要参考API参考以获得更多信息。
public class TimeDecoder extends ReplayingDecoder<Void> {
@Override
protected void decode(
ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
out.add(in.readBytes(4));
}}
此外,Netty提供了现成的解码器,使我们能够非常容易地实现大多数的协议,并帮助您避免使用一个单一的不可维护的处理程序实现。有关更多详细示例,请参阅以下示例:
二进制协议实现: Netty实践-factorial服务器
基于文本行的协议实现: Netty实践-telnet服务器
相关问答
更多-
netty怎么取得tcp传输来的数据[2022-10-04]
使用netty5建立一个TCP的服务端进行接收数据,发送的...特别是你传输的数据比较大时,我用的方法是自定义...小技巧:教您如何更快获得可用分 -
netty如何使用[2022-05-14]
和spring , 先写一个类,然后与一般的bean同样配置Netty怎么传输很长的xml字符串[2023-04-30]
自己实现通讯协议,在消息头加上消息的长度。 缺点,使用如telnet测试的时候,由于没法在输入的字符串里加入消息长度而得到不服务器的反馈, 再如用HTTP等直接访问得到的消息是:消息长度头+消息内容,也没法直接使用。 只能在自己的程序之间使用这种协议, 不能提供给第三方直接访问,例如在浏览器里使用AJAX返回xml。您可以针对Netty运行AutoBahn测试。 它包括一些性能测试。 有关说明,请参阅此处的netty 4和此处的netty 3。 You can run the AutoBahn tests against Netty. It includes some performance tests. For instructions, see here for netty 4 and here for netty 3.while(is.read(buf) > 0) { os.write(buf); } 具有数组参数的read()方法将返回从流中读取的文件数量。 当文件没有完全以字节数组长度的倍数结束时,由于到达文件末尾,此返回值将小于字节数组长度。 不过你的os.write(buf); 调用会将整个字节数组写入流中,包括文件结束后的剩余字节。 这意味着写入的文件最终会变得更大,因此哈希值会发生变化。 有趣的是,当你更新消息摘要时,你没有犯这个错误: while((read = is.read(buffer)) ...Netty TCP推/流服务器(Netty TCP push/streaming server)[2023-07-11]
Nat回答了我的问题 - 在channelActive和channelInactive中添加和删除发送方通道组中的传入通道允许将任意结构的消息推送到订阅客户端。 Nat answered my question - adding and removing the incoming channel from the sender's channelgroup in channelActive and channelInactive allows messages of arbitrary structure ...Netty OIO或NIO(Netty OIO or NIO)[2022-04-05]
很可能你想使用NIO。 如果你真的需要,只使用OIO :) Most likely you want to use NIO. Only use OIO if you really need too :)尝试使用: sendFileFuture = ctx.write(new HttpChunkedInput(new ChunkedFile(raf, 0, fileLength, 8192)), ctx.newProgressivePromise()); Try to use: sendFileFuture = ctx.write(new HttpChunkedInput(new ChunkedFile(raf, 0, fileLength, 8192)), ctx.newProgressivePromi ...只需使用ChunkedWriteHandler并编写一个包装InputStream的ChunkedStream。 这应该完全解决.. Just use ChunkedWriteHandler and write an ChunkedStream that wraps the InputStream. This should work out quite all..当您尝试将ChunkedNioStream写入ChunkedWriteHandler ,它只会生成一个仅包含ChunkedNioStream内容的流。 也就是说,它产生ChannelBuffer而不是HttpChunk 。 因为HttpMessageEncoder只处理HttpMessage和HttpChunk ,所以HttpMessageEncoder生成的ChunkedNioStream被绕过线,没有预先安装HTTP块头,导致浏览器混乱。 要解决这个问题,你必须实现自己的ChunkedInput ,它产 ...