知识点
相关文章
更多最近更新
更多微信获取用户的openid和详细信息
2019-03-02 00:48|来源: 网路
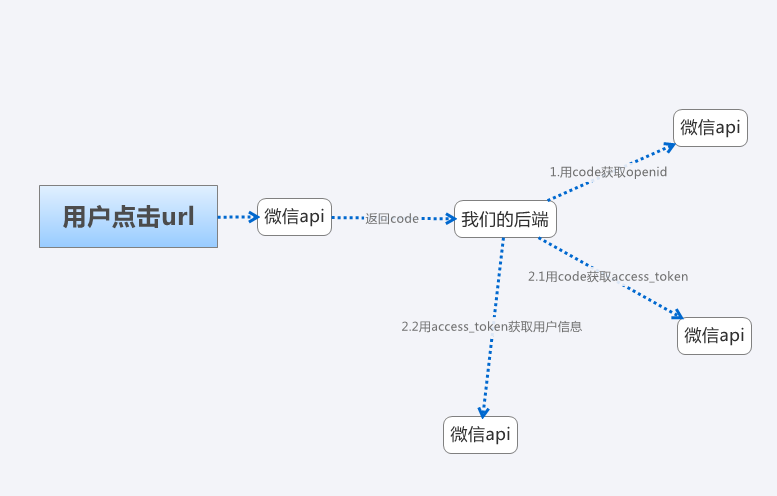
获取用户的信息的原理,首先用户会点击一个url,这个url会包含一个参数redirect_uri,这个url是指向微信那边的服务器的,然后微信会把这个http请求重定向到redirect_uri,即我们的后端,而且会附带一个code参数,如果我们需要获取用户的基础信息(也就是openid)就需要用这个code去访问微信的指定url来请求用户的openid,如果我们需要获取用户的详细信息(微信名称,头像),我们就需要先用code获取一个access_token,再用这个access_token来获取用户的信息
获取用户点击的那个url的方法:
#encoding=utf-8 __author__ = 'kevinlu1010@qq.com' def get_redirect_url(uri, is_info=0): ''' 获取url,改url可以访问微信的网址,然后会重定向回来我们的网址,而且附带访问的微信用户的信息 uri 需要跳转到的uri 如/cherrs is_info 是否获取详细信息,如果为1,就获取用户的详细信息,包括名字,图片,否则就获取基本信息,只有open_id 返回 url ''' pre_url = 'http://xxxx.xxxxx.com' appid = 'wxxxxxxxxxxxxxxxxxeb' scope = 'snsapi_userinfo' if is_info else 'snsapi_base' data = {'redirect_uri': pre_url + uri, 'appid': appid, 'response_type': 'code', 'scope': scope, 'state': '123'} urlencode = urllib.urlencode(data) wei_url = 'https://open.weixin.qq.com/connect/oauth2/authorize?' + urlencode + '#wechat_redirect' return wei_url
通过code获取用户open_id
def get_base_info(code): ''' 通过获取的code,访问微信的api,获取用户基本信息(只有openid) return 用户的open id ''' if not code: return '' url = 'https://api.weixin.qq.com/sns/oauth2/access_token' try: data = {'appid': const.appid, 'secret': const.secret, 'code': code, 'grant_type': 'authorization_code'} post_body = urllib.urlencode(data) f = urllib2.urlopen(url, post_body).read() r = ast.literal_eval(f) #字符串转换成字典 return r['openid'] except: return ''
通过code获取用户详细信息:
def get_detail_info(code): ''' 获取用户的详细信息 return dict {'userID':'','nickname':''m',headimgurl':''} ''' ret = {} url = 'https://api.weixin.qq.com/sns/oauth2/access_token' try: data = {'appid': const.appid, 'secret': const.secret, 'code': code, 'grant_type': 'authorization_code'} post_body = urllib.urlencode(data) f = urllib2.urlopen(url, post_body).read() r = ast.literal_eval(f) #字符串转换成字典 #获取用户详细信息 access_token = r['access_token'] ret['userID'] = r['openid'] url = 'https://api.weixin.qq.com/sns/userinfo?access_token=%s&openid=%s&lang=zh_CN' % ( access_token, ret['userID']) f = urllib2.urlopen(url).read() r = ast.literal_eval(f) #字符串转换成字典 ret['nickname'] = urllib.unquote(r['nickname']) ret['headimgurl'] = urllib.unquote(r['headimgurl']) except urllib2.URLError, e: return ret return ret
转自:http://www.cnblogs.com/Xjng/p/3910511
相关问答
更多-
微信公众平台如何获取用户基本信息 java[2022-02-13]
没有办法的,微信把用户信息控制的很严,只会给开发者一个openId,这是用户的微信号加密后的一串唯一标识 -
java 微信 怎么网页授权获取用户基本信息[2022-06-03]
关于网页授权的两种scope的区别说明 1、以snsapi_base为scope发起的网页授权,是用来获取进入页面的用户的openid的,并且是静默授权并自动跳转到回调页的。用户感知的就是直接进入了回调页(往往是业务页面) 2、以snsapi_userinfo为scope发起的网页授权,是用来获取用户的基本信息的。但这种授权需要用户手动同意,并且由于用户同意过,所以无须关注,就可在授权后获取该用户的基本信息。 3、用户管理类接口中的“获取用户基本信息接口”,是在用户和公众号产生消息交互或关注后事件推送后,才 ... -
微信公众平台开发 OAuth2.0网页授权获取用户基本信息[2023-02-09]
在用户没有关注的情况下,还是会产生一个与公众号对应的openid,可以根据这个openid和基础支持的access_token(不是用code换取的access_token)获取到用户的基本信息 用户信息中的subscribe 是为0的,表示没有关注。 -
我想请问一下,微信对开发者开放的获取微信用户信息的接口是实时的吗?[2023-10-03]
楼主,想问一下 调用获取微信用户信息的接口是可以随时调用,不依赖于其他条件吗?比如小程序中的获取用户信息的接口调用是不依赖于小程序是否启动吗 -
不,这是不可能的。 Google只会发布用户的电子邮件地址。 他们的服务器设置为永不再提供任何更多的信息: 请访问OpenID页面以供开发人员了解更多信息: http : //code.google.com/apis/accounts/docs/OpenID.html No, it isn't possible. Google only releases the user's email address. Their server is set up to never give out any more i ...
-
从openid获取用户详细信息(Get user details from openid)[2023-09-24]
请阅读手册: http : //code.google.com/p/lightopenid/wiki/GettingMoreInformation $openid->required = array('namePerson/friendly', 'contact/email'); $openid->optional = array('namePerson/first'); 在调用$ openid-> authUrl()之前! 然后 $openid->validate(); $userinfo = $ope ... -
检索驱动器时,它返回包含显示名称的所有者对象,但OneDrive API当前不支持电子邮件。 此问题跟踪添加该支持。 I solved it as: ODClient.clientWithCompletion({ (client, error) -> Void in if(error == nil){ odClient = client self.getUserDetails() } }) func getUserDetails(){ odClien ...
-
从Twitter获取用户详细信息(Get user details from Twitter)[2024-01-24]
我处理这个问题的方法是使用: $username = ''; // Twitter Username $page_data = file_get_contents("https://api.twitter.com/1/users/show.json?include_entities=true&screen_name=$username"); 然后使用preg_match()搜索$page_data以获取所需的特定详细信息,以匹配您正在查找的数据的正则表达式模式。 我也发现了这一点,它是沿着相同的路线,但没 ...