知识点
相关文章
更多最近更新
更多Real-Time Rendering 笔记 --- 1-4章
2019-03-02 23:42|来源: 网路
里面有些公式和矩阵无法在电脑上书写, 故用纸笔记录了一些笔记, 比如公式的推算, 注意要点等. 由于电子书是黑白图, 不好理解, 所以弄了彩色配图上来
Chapter 1 Introduction
1. 实时渲染---图像在计算机上快速的显示
2. 15fps --- 实时渲染的基本fps. 72fps以及更大的fps观察者无法发现其中的差别 60fps 对反应时间来说太小了, 只有15ms的时间用于用户反映.
3. 实时渲染的三个条件: 互动, 三维空间, 图形加速
1.1 Contents Overview
4. 各章节介绍
-
Chapter 2 The Graphics Rendering Pipeline: 实时渲染的核心概念
-
Chapter 3 The Graphics Processing Unit: 现代GPU使用固定功能单元和可编程单元实现渲染管线的各个阶段
-
Chapter 4 Transform
-
Chapter 5 Visual Appearance: 材质和光照, 反锯齿, gamma修正
-
Chapter 6 Texturing
-
Chapter 7 Advanced Shading 正确表现材质和点光源的理论和实践
-
Chapter 8 Area and Environmental Lighting
-
Chapter 9 Global Illumination 阴影, 反射, 折射算法, 辐射, 光线追踪, 预处理光照, 环境封闭
-
Chapter 10 Image-Based Effect: lens flares, fire, motion blu, ....
-
Chapter 11 Non-Photorealistic Rendering: cartoon shading
-
Chapter 12 Polygonal Techniques: 讨论多边形数据, 并优化和简化其数据
-
Chapter 13 Curves and Curved Surfaces
-
Chapter 14 Acceleration Algorithms: culling 和 LOD渲染的不同形式
-
Chapter 15 Pipeline Optimization 发现和解决瓶颈
-
Chapter 16 Intersection Test Methods 相交检测
-
Chapter 17 Collision Detection 碰撞检测
-
Chapter 18 Graphics Hardware 颜色深度, 帧缓存, 基本结构体类型, 一些有代表性的图形加速器研究
-
Chapter 19 The Future
1.2 Notation and Definitions (记号和定义)
-
向量使用列向量格式
-
v = {x, y, z, 0} 表示向量, v = {x, y, z, 1} 表示一个点
Chapter 2 The Graphics Rendering Pipeline
-
Bresenham's line-drawing algorithm[142], symmetric double-step algorithm[1391]
-
渲染管线的速度取决于管线中最慢的环节, 无论其他的环节速度多快
-
粗略的将实时渲染管线划分为三个环节: application, geometry, rasterizer
-
概念环节(application, geometry, rasterizer) conceptual stages, 功能环节 functional stages, 管线环节 pipeline stages的区别
-
功能环节 ---- 执行特定的task, 不管如何在管线中实现
-
管线环节 ---- 和其他的管线环节同步
-
也许多个功能环节合并成一个管线环节, 也许一个功能环节分割成多个管线环节
-
-
两个用来表示渲染速度的方式: fps 和 Hertz(Hz)
-
例子: 计算渲染速度
-
假设输出设备的最大更新频率为 60 Hz, 渲染管线的瓶颈环节已经发现, 为62.5ms.
-
渲染速度的最大值为 1/0.0625 = 16fps
-
60/1 = 60Hz, 60/2 = 30Hz, 60/3 = 20Hz, 60/4 = 15Hz, 60/5 = 12Hz
-
15Hz 是小于16fps之下的最大值, 所以最后预计渲染速度为15fps.
-
-
-
-
application stage --- 运行于 CPU, 常处理 碰撞检测, global acceleration algorithm, 动画, 物理模拟以及其他
-
geometry stage --- 通常使用GPU, 常处理 transforms, projections
-
rasterizer stage --- 渲染前面生成的图像, 完全在GPU上处理.
2.2 The Application Stage
-
开发者可完全控制该阶段
-
为了提供性能, 在多核处理器上平行运算, superscalar construction. 见15.5介绍的利用多核处理器的方法
-
该阶段常处理碰撞检测. 处理输入(键盘, 鼠标, ...), 纹理动画. 以及其他阶段不会执行的计算.例如 Chapter 14 介绍的 hierarchical view frustum culling.
2.3 The Geometry Stage
-
处理大部分的顶点和多边形操作.分为以下几个功能环节: model and view transform, vertex shading, projection, clipping, screen mapping
-
模型转换后, 模型处于世界空间/世界坐标系中.
-
视图转换, 让相机处于原点, 且朝向为z负轴, 向上的方向为y轴, x轴为向右.
-
确定材质上光照效果的操作为 shading. 其包含在对象的顶点上计算 shading equation. 该计算有一部分在geometry环节执行, 另一部分在每个像素的光栅化(rasterization)执行, 存储在每个顶点上的一系列材质数据如位置, 发现, 颜色以及其他用于计算shading equation的信息. Vertex shading的结果发送给rasterization环节进行插值. (结果可为颜色, 向量, 纹理坐标以及其他类型的shading数据)
-
Shading 计算通常在世界空间中进行, 实际上, 为了方便有时转换相关实体(如相机和光源)到其他的空间(模型或视觉空间), 并在该空间进行计算.`
-
这是由于光源, 相机和模型的相对关系在转换至其他空间时仍会保持相同的相对关系.
-
-
shading之后就是执行 projection, 主要将视图锥转换至一个单元立方体, 范围为[-1, -1, -1]到[1, 1, 1]. 该单元立方体称为 canonical view volume.
-
两种projection方法: 正交和透视投影
-
投影之后, 模型位于 normalized device coordinates.投影之后, z坐标春处于 z缓存(深度缓存)中.
-
对部分在视图锥之内, 部分在视图锥之外的图元进行裁剪,
-
用户可以定义额外的裁剪平面. 在可编程处理单元(programmable processing units)进行
-
裁剪环节和屏幕映射环节(screen mapping stage)通常有固定操作硬件处理.
-
screen mapping环节, 将裁剪坐标x,y转换成屏幕坐标.
-
像素整数值和浮点值之间的关系: 一个像素的中心坐标为(0.5, 0.5), 所以像素范围[0, 9]可取值[0.0, 10.0)
-
Opengl将左下角的坐标作为最小值, DX将左上角的坐标作为最小值
2.4 The Rasterizer Stage
-
光栅化 --- 计算和设置绘制对象的像素颜色. 将屏幕空间中的二维顶点(带z值)以及每个顶点关联的各种shading信息转换至屏幕上的像素.
-
Rasterizer stage 划分为几个功能环节: triangle setup, triangle traversal, pixel shading, merging
-
triangle setup --- 计算三角形表面的差异和其他数据. 这些数据用于 scan conversion和各种各样shading数据的插值, 由固定操作硬件完成该功能.
-
triangle traversal --- 检查一些像素, 这些像素的中心点被三角形所覆盖. 并生成用于三角形上像素的片段.
-
查找在三角形之内的样本(sample)或像素的操作成为 triangle traversal 或 scan conversion.
-
通过三角形三个顶点的数据插值生成三角形片段(fragment)的性质. 这些性质包括片段的深度以及有geometry环节生成的shading 数据
-
Pixel shading --- 每个像素的shading计算, 输入数据为shading数据的插值结果, 输出数据为一个或多个颜色.该环节由可编程GPU来执行.
-
pixel shading环节可运用许多技术, 其中最重要的为texturing, 即将图片粘贴至模型上
-
Merging环节 --- 将shading环节产生的片段颜色和存储在color buffer里的颜色组合起来, 执行该环节的GPU子单元并非可完全编程的. 但其可进行各种配置, 实现各种效果.
-
Merging 环节还解决对象是否可视问题, 当渲染整个场景之后, 颜色缓存应当存储相机视图在该点可见图元的颜色. 对大多数图形硬件来说, 这点是由 Z-buffer 算法完成. 每个像素存储距离相机最近图元的z值,
-
Z-buffer算法可以以任意顺序渲染大多数图元, 然而对于半透明图元则不能够任意顺序绘制, 必须绘制所有不透明图元之后, 以back-to-front顺序绘制.
-
除了 Z-buffer, color buffer缓存, 还有 alpha channel, 可进行 alpha test.在 depth test之前进行. 该测试的典型用法是确保完全透明的fragment不会影响到 Z-buffer.
-
stencil buffer --- 记录渲染图元的位置, 每个像素八位数据.使用不同的函数图元渲染至stencil buffer.并且buffer的内容可用于控制是否渲染至color buffer 和 Z-buffer.
-
accumulation buffer -- 累积缓存.使用一系列操作对图像进行累积. 例如通过平均和累积图像可以生成 motion blur., 其他效果如 depth of field, antialiasing, soft shadow, etc.
-
double buffer --- 在 back buffer 进行渲染, 而后和 front buffer进行交换, 在 vertical retrace(真扫描)时进行交换.
2.5 Through the Pipeline
-
想象一个互动的CAD应用程序, 用户检查一个移动手机的设计, 透视投影. 手机模型有线条(边缘), 有三角形(表面), 有纹理(显示键盘和屏幕). 在 geometry 环节计算 shading, 除了纹理部分, 该部分在 rasterization 环节发生.
-
Application 环节: 设置旋转矩阵进行手机翻盖操作, 设置相机以不同的位置和视角来浏览手机, 形成一个动画.
-
Geometry 环节 --- 模型矩阵和视图矩阵结合成模型视图矩阵, 将对象所有的顶点和法线转换至视图空间, 计算顶点的shading, 使用材质和光源属性.执行投影, 转换对象之单元立方体空间. 而后进行裁剪. 将顶点映射至屏幕上的窗口. 最后进行光栅化
-
Rasterizer 环节 --- 所有的图元进行光栅化, 转换成为窗口上的像素.进行纹理操作, 通过Z-buffer算法查看对象的可视性, 还有alpha测试, stencil 测试等.
Conclusion
-
offline rendering pipelines 也有不同的发展, 用于电影产品的渲染常使用 micropolygon pipelines,
-
本书默认使用可编程功能管线,
Further Reading and Resources
-
A Trip Down the Graphics Pipeline.
Chapter 3 The Graphics Processing Unit
-
相对于软件, 专用硬件可以提高速度
-
渲染管线的GPU实现: Vertex Shader()->Geometry Shader()-->Clipping(*)-->Screen Mapping(&)-->Trangle Setup(&)-->Triangle Traversal(&)-->Pixel Shader()-->Merger(**)
-
(*) 表示可完全编程的环节
-
(**) 表示可配置但不可编程的环节
-
(&) 表示完全固定功能的环节
-
3.1 GPU Pipeline Overview
-
vertex shader是完全可编程环节, 处理"Model and View Transform", "Vertex Shading" 和 "Projection" 功能环节.
-
geometry shader 是可选的, 完全可编程的环节, 操作图元上的顶点(点, 线, 三角形), 用于执行图元shading操作, 销毁图元, 创建图元
-
clipping, screen mapping, triangle setup, triangle traversal 环节都是固定功能环节.
-
pixel shader为可编程环节, 执行"Pixel shading".
-
merger 环节则为可编程和固定功能之间, 可进行很多配置来完成各种操作. color buffer, Z-buffer, blend, stencil和其他相关缓存.
3.2 The Programmable Shader Stage
-
现代shader环节(支持Shader Model 4.0)使用 common-shader core. 这表示 vertex, pixel, geometry shader 共享一个程序模型(programming model)
-
早期的 GPUs 在顶点和像素 shaders 有很少的共同点, 并且没有 geometry shader.
-
类C语法的着色语言: HLSL, Cg, GLSL, 这些语言编译至无关机器的汇编语言, 即 intermediate language(IL), 该汇编语言通常在驱动中转换至机器语言. 该汇编语言可看成虚拟机. 该虚拟机是一处理器, 可处理不同的register类型和数据类型, 通过一系列的指令编程. 有 4路 SIMD(single-instruction multiple-data)能力. 每个register也有四个独立的值. 基本数据类型为32位单精度浮点数和向量. 支持32位整数.
-
一个 draw call 请求图形API绘制一组图元. 引起图形管线的执行. 每个可编程shader环节有两个类型的输入: uniform input 和 varying input.
-
uniform inputs 在整个 draw call中保持不变. (但在 draw calls之间可以变化)
-
varying inputs 则不同
-
纹理可看成 uniform input, 但是其也可以作为其他纹理的索引数组数据.
-
可通过只读的constant register 或 constant buffers来访问 Uniform inputs.
-
-
虚拟机还有通用的 temporary registers, 用于 scratch space. 所有registers的类型都可以用temporary registers中的整数值来进行数组下标.
-
最快的操作时标量和向量乘法, 加法, 以及之间的组合, 如点乘. 其他的操作如求倒数(reciprocal), 平方根, sin, cos, 指数和对数都相对耗时.
-
shader支持两种类型的流控制: static流控制用于uniform输入. dynamic流控制用于 varying 输入
-
shader程序可以在程序加载之前或者运行期进行离线编译, 可通过设置选项来生成不同的输出文件, 以及使用不同的优化等级.
-
一个编译的shader存储为一文本字符串. 通过驱动传送给GPU
3.3 The Evolution of Programmable Shading
-
用于shader设计的 visual shader graph system: mental mill
-
2007年发展出Shader Model 4.0, 主要特性有 geometry shader 和 stream output.
-
新的程序模型如NVIDIA的CUDA和AMD的CTM用于non-graphics applications
3.3.1 Comparison of Shader Models
-
表3.1 Shader Model 2.0, 3.0, 4.0的区别
3.4 The Vertex Shader
-
在DX中, Vertex Shader环节之前的数据操作成为 input assembler. 将一些数据流组织成一系列顶点和图元发送给管线.
-
在 input assembler 中支持 使用instancing, 即一个对象使用不同的数据可以通过复制来绘制多次.
-
在DX10中, input assembler 会给每个instance(实例), 图元, 顶点一个唯一的数字作为标记, 以便后来的shader可以访问.
-
对于 triangle mesh而言, 在vertex shader中不关心哪些顶点形成哪些三角形, 只处理那些输入的顶点.
-
vertex shader, 每个传送进来的顶点, 输出所在三角形或线条的一系列插值, 不能创建和销毁顶点, 一个顶点的结果不能影响到另外一个顶点. 所以每个顶点都是独立处理的, 多个shader processors在GPU里可以平行处理输入的顶点数据流.
-
vertex shader 可以实现的效果: shadow volume, 活动关节的顶点混合(见超级宝典), silhouette rendering
-
Lens effect, 屏幕显示鱼眼效果, 水下, 以及其他的扭曲效果
-
Object definition, 创建mesh一次, 并通过 vertex shader变形
-
Object twist, bend, taper operation
-
Primitive creation, 通过发送退化(degenerate)mesh给后面的管线, 并在需要的时候给予这些mesh空间. 这个功能在更新的GPU中被geometry shader替代.
-
Page curls, heat haze, water ripples, 通过将整个帧缓存的内容作为纹理贴在屏幕对齐的mesh上, 而后进行程序变形操作.
-
Vertex texture fetch. 用于将纹理作用于顶点mesh, 这样可以让海洋表面, 地形高度图的渲染耗费更小.
-
-
Vertex shader的输出有几个用法, 常用的方法是生成和光栅化每个实例(instance)的三角形, 产生的各自像素片段发送给像素着色器程序. Shader Model 4.0则可将vertex shader的输出发送给geometry shader.
3.5 The Geometry Shader
-
geometry shader 位于 vertex shader之后, 可选的.
-
geometry shader 的输入是 单个对象和它的顶点. 对象通常为一个网格内的一个三角形, 一个线段或者一个点. 另外, 可以额外传送三个三角形外的三个顶点, 在一个多边形可用2个相邻的点.
-
geometry shader 的输出是另个或多个图元, 形式为点, polylines, 三角形带, 多个三角形带. 一个mesh可以被有选择的修改. 方法是编辑顶点, 添加新的图元或者移除其他的图元.
-
geometry shader 对象的输入输出类型不一定需要匹配, 比如输入一个三角形, 而后以点的形式输出三角形的重心, 即使类型符合, 也可以忽略或者扩展每个顶点上的数据. 例如给每个输出后的顶点添加上其所在三角形平面的法线,
-
同 vertex shader, geometry shader 输得的每个顶点都位于裁剪空间位置上.
-
geometry shader 确保图元的输出次序和输入的次序一样. 这个会影响到性能. 为了性能和效率之间的平衡, 每次执行的限制总数为1024 32位值.所以不推荐大量拷贝一个模型, 或者将tesselation表面转换成详细的三角形mesh. geometry shader 环节更多用于修改输入的数据或者进行有限的拷贝. 而不要用于大量的拷贝或扩充.
-
geometry shader 算法: 根据点的数据创建不同大小的粒子, extruding fins along silhouettes, 阴影算法中的查找对象边缘
-
Shader Model 4.0 提出一个专用词 stream output, 在顶点被vertex shader(和 geometry shader)处理之后, 可以输出至流(stream)中, 例如, 一个有序数组, 除了可以发送至光栅化环节, 还可以完全关掉光栅化, 管线使用non-graphical stream processor. 数据通过这样的方法发送回管线, 这样就可以进行迭代重复处理. 这类型的操作对于模拟流水或者其他粒子效果很有用.
3.6 The Pixel Shader
-
在 vertex 和 geometry shader 之后, 图元被裁减并开始光栅化, 这部分在管线中相对固定了功能, 而不是可编程部分. 每个三角形处理其内的区域, 该区域内进行插值得到顶点数据. 下一步是进行pixel shader环节, OpenGL也称之为 fragment shader. 这是由于每个三角形完全或者部分覆盖了pixel's cell. 并且材质为不透明或者透明的. 在merging环节中, fragment的数据用于修改存储与像素中的内容.
-
vertex shader程序的输出为pixel shader程序的输入, 总共16个vector(每个有4个值)从vertex shader发送给pixel shader, 如果是 geometry shader, 则输出16个vector发送给pixel shader.还可以输出额外的内容给pixel shader, 例如用输入flag表示三角形的那一面可见, 片段的屏幕位置.
-
pixel shader程序执行后, 它不能将它的结果直接发送给相邻的pixel, 它使用来自顶点的插值数据和存储的常量和纹理数据, 计算只影响单个像素的结果. 不过这个限制并非非常严格, 可使用图像处理技术来影响相邻像素, 见10.9
-
pixel shader 可以访问用于相邻像素的信息, 该信息是 gradient 或 derivative信息的计算.通过沿屏幕的x轴和y轴改变每个像素, 就可以得到任意值以及计算其总量. 对于不同的计算和纹理寻址非常有用. 这些 gradients 对于一些操作非常重要, 例如 filtering. 大多数GPU通过处理2x2一组像素来实现这个功能. 当 pixel shader 请求一个 gradient 值时, 返回相邻像素的差异值. 这个实现的一个结果是不能够被动态流控制(dynamic flow control)影响的部分访问 gradient 信息---一组中的所有像素必须由相同的指令(instructions)处理. 即使在离线(offline)渲染系统, 也有着这基本限制. 只有 pixel shader 能够访问 gradient 信息.
-
Pixel shader 程序设置用于在merging环节中merging(融合)的片段颜色. 在pixel shader中可以修改光栅化环节生成的深度值, 但不能修改stencil缓存的值, 但stencil值可以传递给merge环节. 在pixel shader 执行雾计算和alpha测试.
-
multiple render targes(MRT), 每个片段可以生成多个向量, 并将其保存至不同的缓存中. 这些缓存必须有相同的尺寸大小, 一些结构(architectures)要求这些缓存有相同的位深度(bit depth), 与颜色缓存不同, 对于这些额外的内容会有一些限制. 例如不能执行反锯齿.
3.7 The Merging Stage
-
merging 环节 --- 各个片段的颜色和深度值与帧缓存组合在一起. 该环节可进行 stencil-buffer 和 z-buffer 操作, 颜色混合操作. 该环节可以进行高度配置, 例如颜色混合的方式, DX10增加了一个功能, 两个来自pixel shader的颜色可以和帧缓存颜色混合, 称之为 dual-color blending.
-
如果MRT功能可使用, 则混合可以发生在多个缓存中. DX10.1 可以对每个MRT缓存实行不同的混合操作.
3.8 Effects
-
shader都不是孤立使用的, 要配合其他shader和固定功能管线部分.
-
一些组织开发了不同的effects language, 例如 HLSL FX, CgFX, COLLADA FX, 每个effect file包装了所有需要的相关信息用于执行特定的渲染算法. 其定义了可供应用程序使用的全局参数.
-
Figure3.8 Gooch shading.
-
NVIDIA's FX Composer 2 effects system
-
DirectX 9 HLSL effect file
-
一个 Gooch shading 的简单实现
-
Gooch shading 的一部分是用表面法线和光源的位置进行比较. 如果法线朝向光源, 则使用 warm tone 着色, 否则使用 cool tone.
-
在两个用户定义的颜色进行插值. 这是non-photorealistic 渲染的一种形式.
-
Effect 变量定义于文件的开头部分, 关于相机位置的参数会自动跟踪. float4x4 WorldXf : World; float4x4 WorldITXf : WorldInverseTranspose; float4x4 WvpXf : WorldViewProjection;
-
语法形式为 type id : semantic
-
float4x4为用户定义, 用于矩阵. id 则是内置名称. WorldXf 是模型至世界转换矩阵, WorldITXf 则是前者矩阵的逆矩阵. WvpXf 为模型空间至相机裁剪空间的矩阵, 这些值由应用程序提供, 不显示于用户接口
-
用户定义变量 float3 Lamp0Pos : Position < string Object = "PointLight0"; string UIName = "Lamp 0 Position"; string Space = "World"; > = {-0.5f, 2.0f, 1.25f}; float3 WarmColor < string UIName = "Gooch Warm Tone"; string UIWidget = "Color"; > = {1.3f, 0.9f, 0.15f} float3 CoolColor < string UIName = "Gooch Cool Tone"; string UIWidget = "Color"; > = {0.05f, 0.05f, 0.6f}
-
尖括号内为注释. 大括号内为缺省值, 注释对于effect或shader编译器无效果, 但可被应用程序查询. 描述如何在用户接口内显示这些变量
-
用于shader输入和输出的数据结构定义 struct appdata { float3 Position : POSITION; float3 Normal : NORMAL; }; struct vertexOutput { float4 HPosition : POSITION; float3 LightVec : TEXCOORD1; float3 WorldNormal : TEXCOORD2; };
-
appdata定义模型上每个顶点上的数据, 用于vetex shader的输入. vertexOutput 则是vertex shader的输出和pixel shader的输入.
-
vertex shader 程序如下: vertexOutput std_VS(appdata IN){ vertexOutput OUT; float4 No = float4(IN.Normal, 0); OUT.WorldNormal = mul(No, WorldITXf).xyz; float4 Po = float4(IN.Position, 1); float4 pW = mul(Po, WorldXf); OUT.LightVec = (Lamp0Pos - Pw.xyz); OUT HPosition = mul(Po, WvpXf); return OUT; }
-
pixel shader 程序如下 float4 gooch_PS(vertexOutput IN) : COLOR { float3 Ln = normalize(IN.LightVec); float3 Nn = normalize(IN.WorldNormal); float ldn = dot(Ln, Nn); float mixer = 0.5 * (ldn + 1.0); float4 result = lerp(CoolColor, WarmColor, mixer); return result; }
-
一个 effect 文件可以有一些函数组成, 也可包括其他 effects 文件的函数
-
一个通道pass由一个vertex和一个pixel shader 组成, 以及一些用于该通道的状态设置. 一个技术technique则有一个或多个passes产生想要的效果.下面的文件则有一个technique, 该technique有一个pass technique Gooch <string Script = "Pass=p0;";>{ pass p0 <string Script = "Draw=geometry;";>{ VertexShader = compile vs_2_0 std_VS(); PixelShader = compile ps_2_a gooch_PS(); ZEnable = true; ZWriteEnable = true; ZFunc = LessEqual; AlphaBlendEnable = false; } }
-
多个 technique 可存储于相同的effect文件.用于不同的shader model(SM2.0, SM3.0等)
-
一个effect包装了相关的techniques, 一系列的方法已发展出来用于管理一系列shaders.
-
Further Reading and Resources
-
David Blythe在DirectX 10上的论文, 关于现代GPU官仙和它们的设计背后的关联
-
访问 ATI和NVIDIA开发者网站访问最新技术的信息, 免费的 FX Composer 2 和 RenderMonkey interactive shader 设计工具来试验我们的shader
-
GLSL, HLSL
-
O'Rorke的文章提供可读的introduction有效的管理shaders.
-
Cg语言提供了一个抽象层, 到处许多主要APIs 和平台. 也提供插件工具用于主要模型和动画包. Sh metaprogramming language更抽象. 为C++库用于映射相关的图形代码至GPU中.
-
如果想要高级 shader techniques, 阅读 GPU Gems 和 ShaderX 系列书籍作为开始. Game Programming Gems 书籍也有一些相关的文章.
-
DirectX SDK 有许多重要的 shader 和算法例子.
Chapter 4 Transform
What if angry vectors veer Round your sleeping head, and form. There's never need to fear Violence of the poor world's abstract storm. --- Rober Penn Warren
-
线性变换是向量加法和标量惩罚 f(x) + f(y) = f(x+y) kf(x) = f(kx) f(x) = 5x; 是一个线性变换, 为缩放变换
-
旋转变换是另一种线性变换. 所有用于3元素向量的线性变换, 可以用 3x3 矩阵表示
-
将一个固定的向量加到另一个向量上是执行一个移动变换
-
仿射变换(affine transform) --- 组合线性变换和移动. 存储与4x4矩阵中.
-
Homogeneous Notation (齐次表示法), p = {x, y, z, w}; w = 1时表示点, w = 0时表示为向量. 如果w!=1且w!=0, 则需要进行齐次化才能得到该点, 即所有的元素除以w. (x/w, y/w, z/w, 1) 矩阵为 4x4形式. 具体内容见 P905 A.4 Homogeneous Notation
-
仿射矩阵 translation, rotation, scalling ,reflection, shearing(切变矩阵), 在变换前后平行的线条依然保持平行. 至于大小和之间角度可能有所变化.
-
本章主要内容: 基本的仿射变换, 更加特殊的矩阵, 四元组, 顶点混合和变形, 投影矩阵.
-
表 4.1 T(t) 移动矩阵 Rx(p) 旋转矩阵 绕x轴旋转 R 旋转矩阵 S(s) 缩放矩阵 Hij(s) 切变矩阵 E(h, p, r) 欧拉变换 Po(s) 正交投影 平行投影至一平面或一锥体 Pp(s) 透视投影 slerp(q, r, t) slerp transform 建立一四元数的插值函数
4.1 Basic Transform
-
基本变换 translation, 旋转, 缩放, 切边, 转换链接(transform concatenation), 缸体变换, normal transform, 逆变换.
-
orientation matrix 是一个旋转矩阵.
-
trace 定义 p898
-
一个矩阵M的trace, 表示为 tr(M), 为一个矩阵对角线元素的和.
-
旋转矩阵3x3中, tr(R) = 1 + 2cos(a)
-
-
旋转矩阵的行列式为1, 且相互正交.
-
uniform(isotropic) scaling, nonuniform(anisotropic) scaling.
-
实现 uniform scaling方法, 除了修改m11, m22, m33元素, 还可以通过修改m44元素来实现. 只需要是缩放的倒数放在该处即可实现uniform scaling. 不过如果后面有 homogenization 操作, 由于产生除法所以很没有效率
-
缩放矩阵, 如果s为辅助, 则表示为反射矩阵或者镜像矩阵. 注意反射矩阵会导致一个三角形的顶点顺序由逆方向变为正方向从而导致错误的光照和 backface culling. 检查一个矩阵是否有反射, 只需要检查 3x3矩阵的行列式是否小于0.
-
沿任意基本坐标系进行缩放的变换, 有三个轴fx, fy, fz表示进行缩放的标准轴, 具体方式见 P59
-
Shearing(切边)用于扭曲整个场景产生一个迷幻(psychedelic)的效果或者根据jittering创建一个 fuzzy reflection.
-
有六个基本切变矩阵: Hxy(s), Hxz(s), Hyx(s), Hyz(s), Hzx(s), Hzy(s), 第一个下标表示那个坐标被改变,第二个下标表示用于改变其他坐标的坐标
-
这个切变矩阵和3D数学图形基础的切边不同, 3D数学图形基础是一个坐标改变两个坐标.
-
Hij(s)的逆操作为 Hij(-s)
-
注意切变矩阵的行列式 |H| = 1, 便是模型在切边前后的体积不变
-
变换矩阵的乘法, 次序很重要.
-
刚体变换(rigid-body transform), 变换前后保持长度, 角度, 和旋向性(handedness)
-
与其他的转换不同, 法线的转换需要乘以伴随矩阵的转置矩阵. 伴随矩阵能够保证存在, 但是法线不能保证在之后仍然为单元长度, 所以需要单元化!
-
法线的转换是乘以变换矩阵逆矩阵的转置矩阵. 由于法线是向量, 所以平移矩阵不影响法线. 需要关心的是左上3x3的矩阵. 均匀缩放只影响法线的长度. 剩下的就是旋转矩阵, 由于旋转矩阵的逆矩阵就是转置矩阵, 转置矩阵的转置矩阵就是原矩阵. 所以直接使用原来的旋转矩阵进行变换. 如果只有平移和旋转矩阵, 则法线不需要进行单元化. 如果是均匀缩放, 则最后的法线直接除以该缩放因子, 可以将除以缩放因子的操作直接在法线变换矩阵中进行.
-
计算逆矩阵:
-
如果矩阵只是一些简单变换的相连, 则通过转换参数和改变矩阵次序来求出逆矩阵. 例如M=T(t)R(a), 则M' =R(-a)T(-t)
-
如果矩阵是正交的, 则逆矩阵为其转置矩阵
-
如果不知道具体情况, 则使用伴随矩阵. 可用Cramer'rule(常用), LU decomposition, Gaussian elimination 来计算逆矩阵
-
-
如果只是对向量进行变换, 则逆矩阵的计算仅仅考虑左上的3x3矩阵.
4.2 Special Matrix Transforms and Operations
-
Euler Transform: head(沿着y正轴), pitch(沿着x正轴), roll(沿着z负轴). 欧拉变换是三个矩阵的长发. E(h,p,r)=Rz(r),Rx(p)Ry(h)
-
万向锁问题, 旋转一定的角度造成一个自由度缺失. 例如E(h, p, r) 中的p为Pi/2 大小, 则其中的 h, r则会合并为一个, r为多余的度.
-
hairy ball theorem
-
Euler角可以使用其他的次序进行旋转, 例如 x/y/z次序, z/x/y次序用于动画, z/x/z次序用于动画和物理. 对于z/x/z, 当绕x轴旋转Pi角度时就会产生万向锁.
-
两个 欧拉角的插值很难实现
-
从一个正交矩阵中得到欧拉参数 h, p, r.
-
matrix decomposition --- 返回一个连续矩阵(concatenated matrix`)中里面不同的变换矩阵.
-
matrix decomposition 返回一系列变换的原因:
-
提取一个对象的缩放因子
-
返回特定系统需要的变换.
-
决定一个模型是否仅仅需要刚体变换
-
动画中关键帧的插值
-
从一个旋转矩阵中移除切变.
-
-
我们已经有了连个 matrix decomposition, 从一个刚体变换中得到平移矩阵和旋转矩阵, 从一个正交矩阵中得到欧拉角. 从4x4矩阵的最后一列得到平移矩阵, 从矩阵的行列式是否小于0得到其是否含有镜面变换. 从矩阵中分离出旋转矩阵, 缩放矩阵, 切变矩阵需要更多的工作.
-
Thomas 和 Goldman 提出了方法用于变换的各种类来解决matrix decomposition问题. Shoemake 改进了他们的方法用于放射矩阵. 且他的算法独立于相关的框架, 并分解(decompose)一个矩阵得到刚体变换.
-
围任意轴旋转, 假设有旋转轴 r(rx, ry, rz), 旋转角度a. 首先球基本坐标系r, s, t, 第二个轴s, 方法为取出r中最小的坐标设为0, 另外两个坐标交换, 并将第一个符号取反. 这样s点乘t 等于0, 第三个轴t由这两个轴叉乘得到. 三个轴作为行向量组成矩阵M, 表示从基本轴r, s, t旋转至标准基本轴. 三个轴作为列向量组成矩阵M', 表示从标准基本轴旋转至基本轴r, s, t. 这样得到矩阵 M'Rx(a)M, 就可以进行任意轴的旋转
-
求任意轴的旋转矩阵还有Goldman创建的方法, 具体见3D数学基本这本书.
4.3 Quaternions
-
四元数主要用于旋转和方位. 一个旋转轴和旋转角度的表示方法很容易转换至一四元数. 且四元数可用于方位间的插值.
-
四元数的定义:
-
q = (qv, qw) = iqx + jqy + kqz + qw = qv + qw
-
qv = iqx + jqy + kqz = (qz, qy, qz)
-
i2 = j2 = k^2 = -1, jk = -kj = i; ki = -ik = j; ij = -ji = k;
-
qw成为实部, qv称为虚部
-
q和i的乘法: qi = (qv X rv + rwqv + qwrv, qwrw - qv*rv), X表示叉乘, *表示点乘
-
q和i的加法: q+r = (qv+rv, qw+rw)
-
q的共轭: q^* = (-qv, qw)
-
值: n(q) = (qx2 + qy2 + qz2 + qw2)^(1/2) (平方根)
-
单元四元数: i = (0向量, 1)
-
四元数的逆: q-1 = q*/n(q)^2; --- q的共轭除以q模的平方
-
共轭规则 (q) = q; (q + r)* = q* + r; (qr) = rq
-
模规则: n(q^*) = n(q); n(qr) = n(q)n(r)
-
乘法的线性 p(sq + tr) = spq + tpr; (sp + tq)r = spr + tqr; p,q, r为四元数, s,t为标量.
-
乘法的结合律: p(qr) = (pq)r
-
单元四元数 q表示 n(q) = 1, 表示方法为 q = (sin(a)uq, cos(a)); 其中uq为单元三元素向量, 单元四元数可用于创建旋转和方位.
-
对数: log(q) = (a)uq
-
指数: q^t = sin(at)uq + cos(at)
-
-
单元四元数q, 四元数p表示进行的旋转.qp(q^-1) 表示可以进行任意轴的旋转.
-
-q和q的区别, 旋转相同的量, 但是轴的方向相反
-
两个单元四元数q,r, 用q'表示q的共轭, 则, r(qpq')r' = (rq)p(rq)/ = cpc', c = rq, 为单元四元数, 表示单元四元数q和r的连接
-
四元数转换至矩阵的公式和矩阵转换至四元数的公式见3D数学基础和笔记.
-
四元数的插值工具 s(q, r, t) = (rq-1)tq, 其中r,q为四元数. 更好的方法 slerp(q,r,t)=sin(a(1-t))*q/sin(a)+sin(at)*r/sin(a), 其中cos(a)=qxrx+qyry+qzrz+qwrw
-
由于插值算法包含三角函数运算, 效率不高, 可使用Li[771,772]来进行更快的计算方法.
-
一个曲线, 拥有恒定的速度和加速度为0, 则成为 geodesic 曲线.
-
对于多个四元数进行插值, 每一次使用下一个四元数时, 图形可能会产生巨大的变换, 造成很陡的曲线. 解决方法可以使用某种类型的spline(样条), 具体实现可见3D数学基础p159
-
求方向s至方向t的旋转路径, 1) 单元化s和t, 求出u, u=sxt/|sxu| (叉乘) 2) e = s*t = cos(2a), |sxt|=sin(2a), 而后得到四元组q=(sinauq, cosa), 2a为向量s至向量t的旋转角度, 具体公式见笔记
4.4 Vertex Blending
-
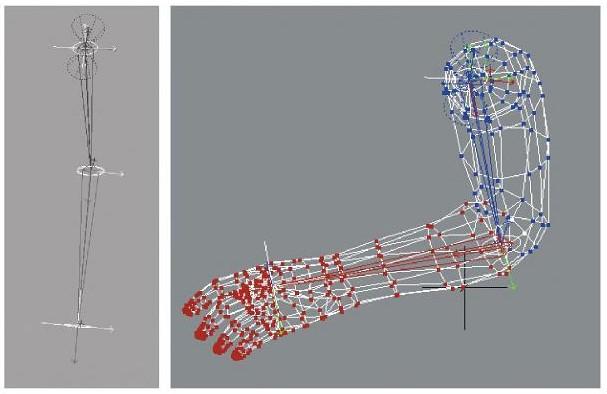
前肢和上臂之间的关节模拟, 使用Vertex blending, 注意缺点在关节的内侧会有折叠部分, OpenGL Superbible有这部分代码的实现.
-
vertex blending 还有其他的名字, skinning, enveloping 和 skeleton-subspace 变形. 最简单的形式, 前肢和上臂各自完成自己的运动. 在关节处则通过塑性"皮肤"来连接, 该处皮肤的顶点分成两部分, 分别由前肢和上臂的转换所影响. 这个技术有时也称为 stitching. 更复杂的形式中, 关节处的顶点同时被多个转换矩阵进行转换, 然后将结果通过权重值混合. 对于这样骨骼上的mesh, 成为skin(over the bones).
-
图4.11: 一个顶点混合的真实例子. 左上角图像显示了一个伸展手臂的两个骨头. 右上角显示了mesh. 图上的颜色显示该顶点被哪个骨头控制. 下面的图像显示了手臂上着色的mesh. (shaded mesh)
-
Mohr和Gleicher[889]提出了一个想法, 通过添加额外的关节实现类似 muscle bulge的效果. James 和 Twigg[599]则讨论animation skinning using bones that can squash and strtch.
-
Vertex Blending使用的公式见笔记
-
mesh中的顶点可以存储于静态缓存, 而后一次发送给GPU并重复使用. 在每一帧中, 只有bone matrices发生变化, vertex shader则计算它们作用于mesh上顶点的效果. 这种方式, 可以最小化GPU中处理和传输的数据, 并有效率的渲染这些mesh. 当整个模型的bone matrics可以统一使用时很简单. 否则整个默病必须进行分割并写复制某些bones.
-
使用 vertex shader时, 可以设置权重值在[0, 1]范围之外, 或者不需要权重总和为1. 这只能用于一些混合算法, 如 morph targets.
-
vertex blend 的缺点是会产生折叠, twisting 和 self-intersection, 一个最好的解决方法是使用 [dual quaternions]. 该方法保持原有转换的rigidity效果, 并避免"糖果纸"的扭曲形状出现在肢体上. 代价是linear skin blending的1.5倍以下, 但产生了极好的效果. 有兴趣者可查看其论文.
4.5 Morphing
-
用于动画, 一个t0时刻的3维模型和t1时刻的模型, 在t0和t1时间内, 使用一些算法能够得到其之间的"混合"模型用于过渡. 例子见图4.13
-
Morphing 有两个主要问题: vertex correspondence(顶点对应) 问题和 interpolation 问题.
-
假设两个模型之间是点点对应的, 计算morph vertex则很简单, t属于[t0, t1], p0和p1则是两个模型对应的点, 则 s = (t-t0)/(t1-t0), m = (1-s)p0 + sp1. 关于面部表情的动画, 两个表情之间有不同的顶点. 则使用 neutral face, 对不同的顶点使用"加法"操作, 加正数权重值得到一个表情, 加负数权重值得到另一个一个表情.
-
对于面部表情动画, 假设使用一个neutral模型, 标记为N, 使用一系列的表情姿势, 记为Pi i=1, 2, ... k. 有k个表情姿势. 在预处理的过程中, 计算"difference faces"(差异表情) Di = Pi - N. 而后我们可以通过公式得到morphed model M. 见笔记本.
-
morph target 是一个非常有用的技术, 使得动画制作者对动画可进行更多的控制. Lewis et al.[770] 介绍了 pose-space deformation, 组合了 vertex blending 和 morph targets 技术. 硬件支持DX10使用stream-out和其他提升的功能来允许更多的target用于单个模型和单独在GPU中计算effects.
4.6 Projections
-
在渲染之前, 所有场景中的objects都必须投影至某种类型的平面或者某种类型的锥体(volume)内, 而后执行裁剪和渲染.
-
向量的w成分用于区分方向和点, 之前的转换矩阵最下面一行通常为(0, 0, 0, 1), 透视投影矩阵的最下面一行包含操作数字和进行齐次处理. 正交投影中w成分没有任何作用.
-
正交投影公式 见笔记, 仅仅抛弃z坐标.
-
正交化更常用的矩阵记为 six-tuple (l, r, b, t, n, f) 分别为, 左, 右, 底, 顶, 近, 远平面, 该矩阵通过缩放和平移AABB(由这六个平面组成)得到一围绕原点且轴对齐的立方体. 该AABB的最小角坐标为(l, b, n), 最大角坐标为(r, t, f).注意其中 n > f. 不过在Opengl的glOrtho函数中, n < f, 可以看成其内部进行了求负操作, 或者看成视觉坐标系中距离原点(眼)的距离. 在OpenGL中, 该轴对齐立方体的最小坐标为(-1, -1, -1), 最大坐标为(1, 1, , 1), 而DX为(-1, -1, 0)至(1, 1, 1). 该立方体称为canonical view volume. 其中的坐标称为 normalized device coordinates(单元化设备坐标), 转换成 canonical view volume 使得裁剪更有效率. 最后的转换矩阵见笔记 公式 4.60.
-
透视投影, 笔记有透视投影矩阵详细的求解
-
透视投影Z坐标和近平面远平面以及深度值变化的关系, 见笔记. 深度值的变化并不是线性变化.
Further Reading and Resources
-
Farin and Hansford's <The Geometry Toolbox>[333], Lengyel's <Mathematrics for 3D Game Programming and Computer Graphics>[761] 用于建立关于矩阵的直觉了解.
-
透视投影则有 Hearn and Baker[516], Shirley[1172], Watt and Watt[1330]. Foley et al.[348, 349], 矩阵的基础, Graphics Gems系列[36, 405, 552, 667, 982]则有不同转换的相关算法. Golub and Van Loan's <Matrix Computations>[419] 则是用来开始矩阵技术的系列学习.
-
http://www.realtimerendering.com 有许多转换的代码, 包括四元数.
-
要了解更多 skeleton-subspace deformation/vertex blending and shape interpolation 阅读 Lewis et al's SIGGRAPH paper.
-
Hart et al.[507]and Hanson[498] 提供了四元数的可视化, Vlachos and Isidoro 提供了四元数的插值. Dougan[276]则是关于在一坐标系统沿着一曲线计算四元数插值的问题.
-
Alexa[16] and Lazarus & Verroust[743] 则有许多morphing技术的介绍


下面是图形Figure3-9


下面是Figure4.11

下面是Figure4.12


下面是Figure 4.13



转自:http://www.cnblogs.com/summericeyl/archive/2011/02/05/1949241
相关问答
更多-
硬实时意味着你必须绝对打击每个截止日期。 很少的系统有这个要求。 一些例子是核系统,一些医疗应用如起搏器,大量防御应用,航空电子等。 固体/软实时系统可能会错过一些最后期限,但如果错过了太多,最终性能会下降。 一个很好的例子是您的计算机中的声音系统。 如果你错过几点,没有什么大不了的,但是想念太多,你最终会降级系统。 类似的是地震传感器。 如果你错过了几个数据点,没有什么大不了的,但是你必须抓住他们中的大部分来了解数据。 更重要的是,如果不能正常工作,没有人会死亡。 这条线是模糊的,因为即使是起搏器也可以在 ...
-
如果你的问题是“是否有可能建立这样一个系统并实时执行这些操作?” 那么我认为答案是肯定的,我认为是。 如果你的问题是“我怎样才能减少上述步骤的数量”,那么我不确定我能否提供帮助,并且会服从这里的专家,迫不及待地想听到答案! 我已经实现了一个系统,我认为它与您在外汇交易算法研究中所描述的类似(例如,将数据从我的笔记本电脑上传到存储,计算引擎工作人员将数据拉出并处理,然后将结果存回存储器,然后下载编译结果从我的笔记本电脑)。 我使用了Google PubSub架构 - 如果您已经阅读过此内容,请致歉。 它允许程 ...
-
我相信这是因为allStrokes.add(drawnStroke); 在调用私有方法touch_up之前touch_up被调用,所以当为了绘图目的迭代allStrokes时,省略当前笔划。 尝试将该行代码移至touch_start 。 I believe this is because allStrokes.add(drawnStroke); is not called until the private method touch_up is called, so when iterating over ...
-
AngularJS - 为什么我无法实时更新我的数组长度?(AngularJS - Why can't I get my array length updated in real-time?)[2022-10-28]
正如@unobf已经说过的,在这种情况下,你应该使用AngularFire的$asArray 。 Firebase会在后台异步加载(并同步)您的数据。 这意味着即使当前用户不是添加任务的用户,它也可能会收到阵列的更新。 发生这种情况时,它需要(除了更新数组外)通知AngularJS数据已被修改。 您可以调用$asObject来处理对象的这种通知,但不是为处理数组而设计的。 为了处理Firebase的有序集合(不使用索引但使用不同类型的键)和AngularJS数组之间的复杂关系,您需要使用$asArray 。 ... -
什么是实时转账?(What's real-time transfer?)[2023-06-19]
我想在这种情况下,这意味着可用带宽不足以流式传输原始视频。 例如30p FullHD将需要1920 * 1080 * 3 * 30 bytes / second = 187 MB/s or 1490 Mb/s带宽,大多数消费者互联网下载速度为2 - 25 Mb / s(当然取决于国家和地区) 。 非实时是等待一分钟观看一秒视频( 1490/25 = 59.6 ),这不是一个愉快的体验。 (缓冲在这里也起作用,但这种解释已经变得太长了。) 压缩使我们能够以比特率看到近乎完美或足够好的视频,这更适合我们的可用带 ... -
您可以选择一个环境,允许您使用像素值填充数组并将其显示为位图。 这样,您最接近于在视频内存中调用RGB值。 WPF,Silverlight,HTML5 / Javascript都可以做到这一点。 如果你不全屏,这些技术现在就足够了。 在WPF和Silverlight中,使用WriteableBitmap。 在HTML5中,使用画布 然后由您来实现绘制直线,圆,贝塞尔曲线,3D投影的逻辑。 这很有趣,你会学到很多东西。 You could pick a environment that allows you ...
-
我能够使它工作! 我没有将.ipnyb文件中的代码复制到gist窗口,而是将整个文件拖放到gist窗口中,并且gist将其渲染为OK! I was able to make it work! Instead of copying the code from the .ipnyb file into the gist window, I dragged & dropped the whole file into the gist window and the gist renders it OK!
-
我认为vPython应该做你的工作。 I think vPython should do your job.
-
目前还不清楚你要去哪里,但是这段代码会产生一个平滑渲染的HTML动画。 虽然创建动画需要一段时间(约一分钟)。 library(animation) library(ggplot2) # your data n <- 1000 df <- data.frame(time=1:n,y=runif(n)) window <- 100 # create the animation saveHTML({ for(i in 1:(n-window)) { print(ggplot(df) + geom_line ...
-
你是绝对正确的。 Readable流仅在完全消耗时才发出end事件。 看看这里: http : //nodejs.org/api/stream.html#stream_event_end You are absolutely right. The Readable stream emits end event only when it is totally consumed. Have a look here: http://nodejs.org/api/stream.html#stream_event_e ...